Kormánypropaganda  2024. április 18. 4
2024. április 18. 4
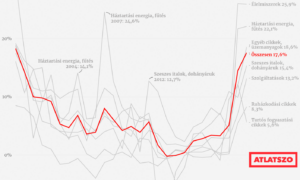
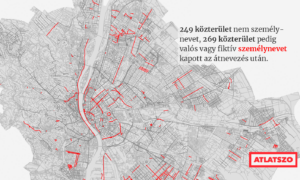
Tavaly a Magyar Nemzet, a Mediaworks és az Origo bukta a legtöbb sajtópert
A személyiségi jogok megsértése terén a Mediaworks lett a rekorder 25 elmarasztaló ítélettel. Az Átlátszó, az RTL és a Telex egy pert sem vesztett el.